
LTX Video 是目前最强的开源视频生成模型之一,但原版模型对显存的要求让很多 4070 甚至 4080 用户望而却步。 好消息是,通过 GGUF 量化技术,我们可以把显存占用压缩到极限,在 12G-16G 显存的设备上流畅运行(实测3060 12G顺利跑通)。
本文将手把手教你如何从零开始部署这套“平民版” LTX Video 工作流。
🛠️ 第一阶段:环境与插件安装
在下载模型之前,我们需要先给 ComfyUI 安装必要的“驱动”插件。
1. 启动 ComfyUI Manager
打开你的 ComfyUI,点击右侧菜单栏的 “Manager” (管理器) 按钮。
2. 安装核心节点
在 Manager 中点击 “Install Custom Nodes”,搜索并安装以下两个插件:
- 搜索关键词:
GGUF- 插件名:
ComfyUI-GGUF - 作者: City96
- 作用:这是核心插件,让 ComfyUI 能识别 .gguf 格式的轻量化模型。
- 插件名:
- 搜索关键词:
KJNodes- 插件名:
ComfyUI-KJNodes - 作者: Lijai
- 作用:提供 LTX Video 所需的 Audio/Video VAE 辅助节点。
- 插件名:
⚠️ 重要: 安装完成后,必须点击 “Restart” 重启 ComfyUI 才能生效。【LTX-2 开源项目地址】
📂 第二阶段:模型下载与文件归位
这是最容易出错的一步。请严格按照以下清单下载,并放入准确的文件夹中。 (如果文件夹不存在,请手动新建)
1. 核心模型下载清单
所有模型均可在 HuggingFace 下载(LTX-2 HuggingFace 存储库)。
同时模型和工作流文件我们会打包到网盘,方便网络不好的小伙伴下载。【夸克网盘下载】
| 模型类型 | 文件名 (推荐) | 存放路径 (ComfyUI目录下) | 备注 |
| Unet (主模型) | ltx-2-19b-distilled_Q4_K_M.gguf | models/unet/ | Q4 版本画质最好,Q2 版本速度最快。 |
| Text Encoder | gemma-3-12b-it-Q2_K.gguf | models/clip/ | 关键文件! 必须用 Q2_K 版本 (约4GB),原版会爆显存。 |
| Connector | ltx-2-19b-embeddings_connector_dev_bf16.safetensors | models/clip/ | 注意:工作流通常需要 dev 版。如果你只有 distill 版,后面需要手动修改节点。 |
| VAE | LTX2_video_vae_bf16.safetensors | models/vae/ | 视频解码器,决定画面色彩和清晰度。 |
2. 目录结构示意图
为了防止放错,你的文件夹结构应该长这样:
ComfyUI/
└── models/
├── unet/
│ └── ltx-2-19b-distilled_Q4_K_M.gguf <-- 主模型放这里
├── clip/
│ ├── gemma-3-12b-it-Q2_K.gguf <-- 语言模型放这里
│ └── ltx-2-19b...connector...safetensors <-- 连接器放这里
└── vae/
└── LTX2_video_vae_bf16.safetensors <-- VAE放这里🔌 第三阶段:工作流搭建 (手术式修改)
如果你下载了网上的标准 LTX 工作流,打开后大概率会报错。我们需要进行一次“心脏置换手术”,把原版加载器换成 GGUF 加载器。
1. 移除旧节点
在工作流画面中,找到红色的报错节点 DualCLIPLoader,直接按 Delete 键删除。
2. 添加新节点
- 在空白处双击鼠标,搜索输入:
DualCLIP。 - 选择出现的
DualCLIPLoader (GGUF)节点(注意名字后缀)。
3. 正确设置节点参数 (关键!)
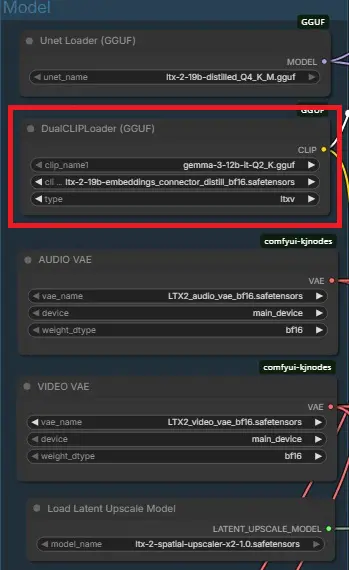
新节点添加后,请按图设置:
- clip_name1: 选择
gemma-3-12b-it-Q2_K.gguf - clip_name2: 选择
ltx-2...connector...safetensors - type: 必须手动选为
ltxv- 注意:默认可能是
sd3或其他,不改的话生成的视频全是雪花噪点!
- 注意:默认可能是
4. 重新连线
- 输出端:将
DualCLIPLoader (GGUF)右侧黄色的CLIP端口拉出线条。 - 输入端:分别连接到 正向提示词 (Positive Prompt) 和 负向提示词 (Negative Prompt) 左侧的
clip端口。
🎬 第四阶段:避坑与参数设置
跑通工作流的最后一步,是设置合理的视频参数。
1. 帧数设置 (Length)
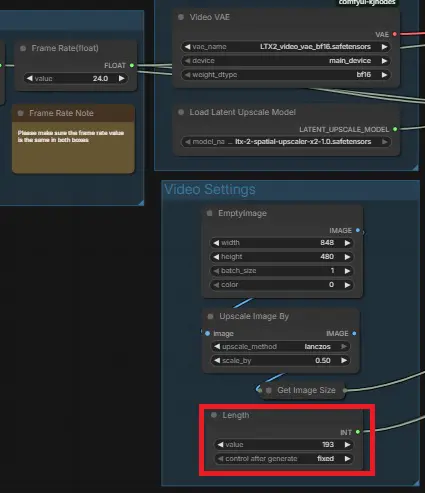
LTX 模型对帧数敏感,必须符合公式:(8 × N) + 1。
- 初次测试(推荐): 设置为 97 (约4秒)。
- 进阶长度: 设置为 129 (约5秒)。
- 硬件极限: 设置为 193 (约8秒)。
- 警告:不要随意设置如 243 帧,这会导致 16G 显存瞬间溢出,系统卡死。
2. 关于“假死”与红字报错
当你点击生成后,可能会看到:
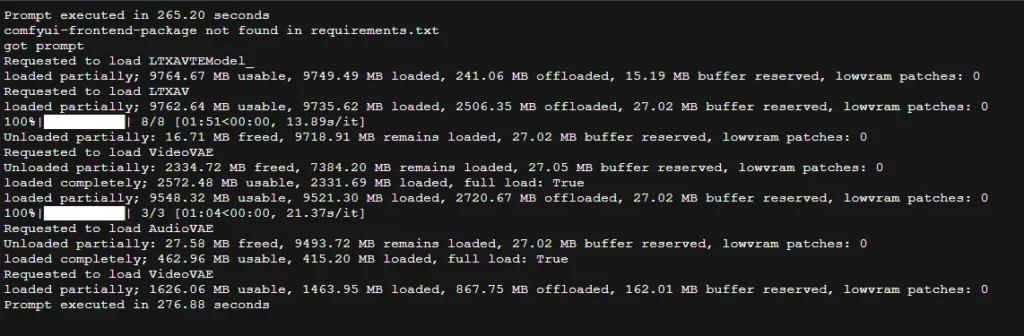
- CMD 窗口提示
loaded partially... offloaded to RAM:这是正常的,说明显存不够用了,系统在用内存硬扛。 - CMD 出现
ConnectionResetError:不要慌! 只要看到最后显示Prompt executed,说明视频已经生成好了。去Output文件夹拿视频即可。
❓ 常见问题解答 (FAQ)
Q1: 为什么我的 DualCLIPLoader 节点报错显示红色?
A: 这通常是因为你选择了错误的文件版本或节点类型。
- 确保你使用的是 DualCLIPLoader (GGUF) 节点,而不是原版的 Loader。
- 检查
clip_name2是否加载了ltx-2-19b...connector文件。 - 最重要的一点: 节点的
type选项必须手动切换为ltxv。如果选成sd3或其他模式,节点会报错或生成噪点。
Q2: 12GB 显存显卡(如 3060/4070)最大能跑多少帧?
A: 在使用 GGUF 量化模型(Q4 Unet + Q2 Text Encoder)的情况下:
- 推荐设置: 97 帧(约 4 秒)。这是最稳定且生成速度较快的档位。
- 极限设置: 129 帧(约 5.3 秒)。可能会触发共享显存(使用内存),导致生成时间变长。
- 不推荐: 超过 161 帧。此时极其容易爆显存,导致系统卡顿或 ComfyUI 无响应。
Q3: 为什么后台出现 ConnectionResetError: [WinError 10054] 报错?
A: 别担心,这不代表生成失败。 当生成视频(特别是解码 VAE 阶段)时,显卡和 CPU 处于满载状态,ComfyUI 后台忙于计算,无法及时响应浏览器的“心跳包”请求,导致网页认为连接断开了。只要后台 CMD 窗口最后显示 Prompt executed in ... seconds,说明视频已经成功生成并保存到了 output 文件夹。
Q4: 生成的视频全是雪花噪点或者灰蒙蒙的,怎么回事?
A: 这通常是两个原因造成的:
- 节点 Type 选错: 请再次检查 DualCLIPLoader (GGUF) 的
type是否选为了ltxv。 - 缺少采样修正: 部分 GGUF 模型需要特定的采样器设置。如果你遇到噪点,尝试在 Unet Loader 后连接一个
ModelSamplingSD3节点,或者尝试将采样器(Sampler)的scheduler改为sgm_uniform或simple进行测试。
Q5: 我可以用这个工作流跑 Image-to-Video (图生视频) 吗?
A: 本教程主要针对 Text-to-Video (文生视频)。 LTX Video 的图生视频功能需要额外的图像输入节点和 Conditioning 处理。虽然 GGUF 模型本身支持,但工作流连线会有所不同。建议先跑通文生视频,熟悉性能极限后再尝试加入图像输入。
Q6: 为什么我的生成速度特别慢(比如 5-10 分钟)?
A: 观察一下控制台是否有 loaded partially... offloaded to RAM 的提示。 如果出现这句话,说明你的物理显存(VRAM)用光了,系统正在使用系统内存(RAM)进行计算。内存读写速度远低于显存,因此速度会变慢 5-10 倍。解决方法是:
- 降低视频帧数(例如从 129 降到 97)。
- 关闭或移除
Upscale(放大) 流程,只生成原生分辨率(768×512 或类似)。
Q7: 我需要下载多大的内存(RAM)才够用?
A: 推荐 32GB 或以上。 虽然 GGUF 极大地降低了显存需求,但模型在加载和卸载过程中依然需要占用大量系统内存。如果你的内存只有 16GB,运行 LTX Video 可能会非常吃力,甚至导致系统死机。
结语
通过以上步骤,你已经成功部署了一套低显存友好的 LTX Video 工作流。GGUF 方案虽然在生成速度上略慢于原版(因为涉及内存交换),但它让普通显卡也能跑出电影级的 AI 视频,绝对值得一试。