
在 NVIDIA 显卡价格依然居高不下的今天,AMD 凭借“大显存、低价格”的错位竞争策略,成为了本地 AI 玩家(尤其是学生党和 HomeLab 爱好者)的“真香”选择。
如果你像我一样,想组装一台性价比最高的 AI 绘图/聊天机器,这篇教程将带你绕过所有深坑,用最优雅的 Docker 方案,榨干 A 卡的每一滴算力。
第一部分:硬件选择——显存即正义
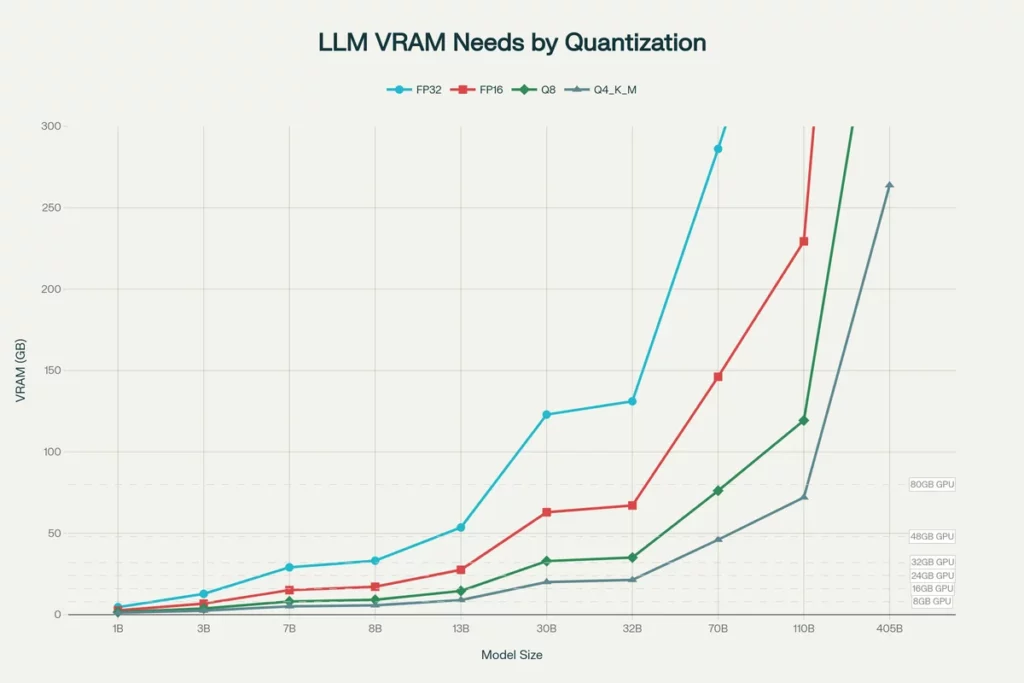
在本地跑大模型(LLM),显存(VRAM)的大小决定了你能跑多大的模型,而算力只决定了生成的速度。AMD 的 RX 6000/7000 系列在这里优势巨大。
| 型号 | 显存 | 定位 | 适合场景 |
| RX 7900 XTX | 24GB | 旗舰 | 全参数微调、70B 大模型量化运行、复杂 ComfyUI 工作流。 |
| RX 7900 XT | 20GB | 次旗舰 | 独特的 20GB 显存,刚好能跑一些 16GB 卡跑不了的 34B/40B 模型。 |
| RX 7800 XT / 6800 XT | 16GB | 性价比 | 入门首选。能流畅运行 SDXL 绘图和 13B 级别 LLM。 |
避坑提示: 尽量避免购买 8GB 显存的显卡(如 RX 7600),在 AI 领域,8GB 很快就会爆显存。
第二部分:物理机环境准备 (Host Setup)
我们以 Ubuntu 22.04 LTS 为例。无论你是用高性能 PC 还是服务器(如 Dell R730),以下步骤必须在宿主机完成。
1. BIOS 关键设置
在插卡开机前,进入 BIOS 开启以下选项,否则模型加载速度会极慢:
- Above 4G Decoding: Enabled
- Re-Size BAR: Enabled (或 Auto)
- PCIe Speed: Gen 3 或 Gen 4 (不要选 Auto,防止掉速)
2. 安装 AMD 驱动 (ROCm)
不要用 apt install 直接装,去 AMD 官网下载脚本。
# 1. 更新系统
sudo apt update && sudo apt upgrade -y
# 2. 运行安装脚本 (以 ROCm 6.1 为例)
# --no-dkms: 推荐物理机使用,减少内核编译麻烦
sudo amdgpu-install --usecase=rocm,graphics --no-dkms
# 3. 关键权限设置 (否则 Docker 无法调用显卡)
sudo usermod -aG render,video $USER安装完成后重启,并在终端输入 rocm-smi 验证。如果你看到类似下图的输出,说明驱动成功:
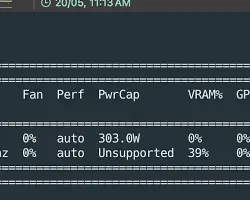
第三部分:Docker 全栈部署 (核心实战)
为了保证环境干净,我们拒绝在宿主机直接装 Python,全部采用 Docker 部署。我们将部署两套核心应用:
- Ollama + Open WebUI: 强大的对话机器人。
- ComfyUI: 最硬核的节点式 AI 绘图工具。
1. 编写 docker-compose.yml
创建一个目录 ai-stack,新建 docker-compose.yml 文件:
version: '3.8'
services:
# --- 聊天服务: Ollama ---
ollama:
image: ollama/ollama:rocm
container_name: ollama
restart: always
devices:
- /dev/kfd:/dev/kfd # 计算调度器
- /dev/dri:/dev/dri # 显卡渲染接口
environment:
# 【关键知识点】显卡架构伪装
# RX 7000系填 11.0.0,RX 6000系填 10.3.0
- HSA_OVERRIDE_GFX_VERSION=11.0.0
# 显存策略:聊天结束后立即释放显存,给绘图让路
- OLLAMA_KEEP_ALIVE=0
volumes:
- ./ollama_data:/root/.ollama
ports:
- "11434:11434"
# --- 聊天界面: Open WebUI ---
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: always
environment:
- OLLAMA_BASE_URL=http://ollama:11434
volumes:
- ./open-webui_data:/app/backend/data
ports:
- "3000:8080"
depends_on:
- ollama
# --- 绘图服务: ComfyUI (ROCm版) ---
comfyui:
image: yanwk/comfyui-boot:rocm
container_name: comfyui
restart: unless-stopped
devices:
- /dev/kfd:/dev/kfd
- /dev/dri:/dev/dri
environment:
- HSA_OVERRIDE_GFX_VERSION=11.0.0
# 16GB 显卡建议使用 normalvram 平衡模式
- CLI_ARGS=--listen --normalvram
volumes:
- ./comfyui_data:/root/comfyui/output
- ./comfyui_models:/root/comfyui/models
ports:
- "8188:8188"2. 启动服务
docker-compose up -d第四部分:实际体验与效果
1. 聊天体验 (Open WebUI)
访问 http://你的IP:3000。第一次进入需要注册管理员账号。在设置中下载 llama3 或 qwen2.5 模型。
得益于 ROCm 的优化,7900 XTX 跑 70B 模型的速度可以达到 15-20 tokens/s,阅读体验非常流畅。
2. 绘图体验 (ComfyUI)
访问 http://你的IP:8188。虽然 A 卡没有 CUDA 加速,但 ROCm 在 Linux 下的效率已经能够达到 N 卡同级别的 80%-90%。使用 SDXL 模型生成一张 1024×1024 的图片,RX 6800 XT 仅需几秒钟。
3. 显存管理策略
这是本文最精华的部分。由于 AMD 显卡不支持硬件级显存切分,我们通过配置实现了**“分时复用”**:
- 当你不聊天时,Ollama 会自动清空显存(
OLLAMA_KEEP_ALIVE=0)。 - 此时打开 ComfyUI,它能独占全部 16GB/24GB 显存,满血绘图。
- 注意: 不要尝试一边画图一边问问题,显卡会因为显存不足(OOM)而报错甚至驱动重置。
第五部分:常见“坑”与解决方案
| 报错现象 | 原因 | 解决方案 |
| Permission denied (/dev/kfd) | 用户权限不足 | 执行 sudo usermod -aG render,video $USER 并重启。 |
| hipErrorNoBinaryForGpu | 驱动不认识消费级显卡 | 检查环境变量 HSA_OVERRIDE_GFX_VERSION 是否填对。 |
| 绘图花屏 / 系统死机 | SDMA 内存传输 Bug | 添加环境变量 HSA_ENABLE_SDMA=0。 |
| Python 报错 CUDA not found | 装错了 PyTorch 版本 | 必须去官网复制 rocm 专用的 pip 命令,别直接 pip install torch。 |
结语
虽然 AMD 的生态不如 NVIDIA 完善,但通过 Linux + Docker + ROCm 的组合拳,我们完全可以花一半的钱,享受到旗舰级的 AI 体验。
对于热衷于 Self-Hosted 的极客来说,这种“折腾”本身就是乐趣的一部分。希望这篇教程能帮你的 A 卡焕发新生!
FAQ (常见问题)
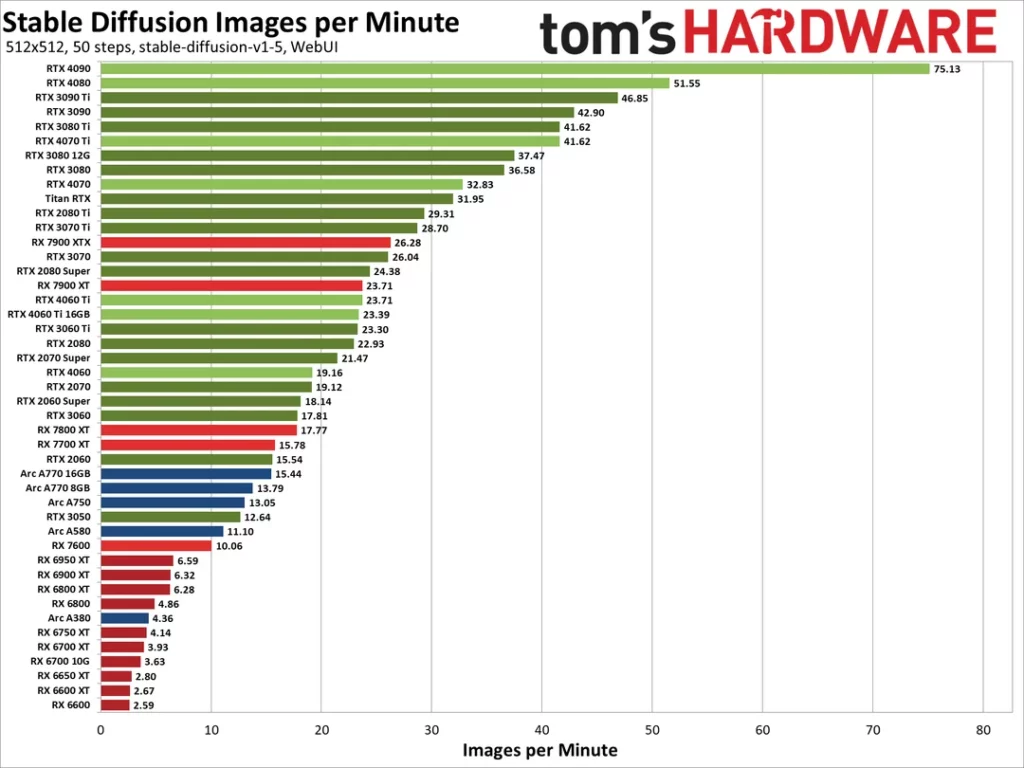
Q1: AMD 显卡跑 AI 绘图 (Stable Diffusion) 速度慢吗?
答: 并不慢。在 Linux (Ubuntu) 环境下配合 ROCm 6.0+ 驱动,AMD RX 6000/7000 系列显卡的绘图性能可以达到同级别 NVIDIA 显卡的 80%~95%。例如,RX 7900 XTX 在 ComfyUI 中生成 SDXL 图片仅需几秒钟。相比 Windows 下的 DirectML 方案,ROCm 的效率有数倍的提升。
Q2: 我必须安装 Linux (Ubuntu) 吗?Windows 能不能跑?
答: 强烈建议使用 Linux (Ubuntu 22.04)。虽然 Windows 目前可以通过 LM Studio 或 HIP SDK 运行部分 AI 应用,但 Docker + ROCm 在 Linux 下的稳定性、生态兼容性(如 PyTorch、Ollama、Flash Attention)以及显存管理效率都远超 Windows。如果你想长期稳定运行,Linux 是必经之路。
Q3: 跑本地大模型 (LLM) 需要多少显存?8GB 够用吗?
答: 8GB 在 2026 年是 入门红线,很容易爆显存。
- 8GB: 只能跑高度量化的 7B 小模型或生成 512×512 图片。
- 16GB (推荐): 本地 AI 的黄金标准(如 RX 7800 XT),可流畅运行 13B-34B LLM 和 SDXL 绘图。
- 24GB (进阶): 适合运行 70B 大参数模型 或进行 LoRA 微调。
🛠️ 资源下载与工具箱 (Resource Toolkit)
以下是本文涉及的所有核心驱动、脚本及 Docker 镜像地址。请注意版本时效性(最后更新:2026年2月)。
1. 核心驱动与系统工具
| 工具名称 | 用途 | 下载/安装命令 |
| AMD GPU Installer | 官方 Linux 驱动脚本 (ROCm 6.x) | 📂 官方仓库入口wget https://repo.radeon.com/amdgpu-install/6.1.3/ubuntu/jammy/amdgpu-install_6.1.60103-1_all.deb |
| Docker Engine | 容器运行环境 (必装) | curl -fsSL https://get.docker.com -o get-docker.sh && sudo sh get-docker.sh |
| ROCm Info | 显卡状态监控工具 | (驱动自带) rocm-smi |
2. Docker 镜像与项目仓库
- 🤖 Ollama (ROCm 版)
- Docker Pull:
docker pull ollama/ollama:rocm - 官方文档: Ollama Linux Setup
- 说明: 记得添加
/dev/kfd设备映射。
- Docker Pull:
- 🎨 ComfyUI (ROCm 优化版)
- 推荐镜像:
yanwk/comfyui-boot:rocm - GitHub 项目: YanWenKun/ComfyUI-Docker
- 说明: 社区维护的 AMD 专用镜像,内置了 PyTorch ROCm 环境。
- 推荐镜像:
- 💬 Open WebUI
- Docker Pull:
docker pull ghcr.io/open-webui/open-webui:main - GitHub 项目: Open WebUI
- Docker Pull:
3. 开发环境 (Python/PyTorch)
如果您不使用 Docker,需要在物理机直接运行 Python 代码,请使用以下源:
- PyTorch (ROCm 6.1 专用源)
- Index URL:
https://download.pytorch.org/whl/rocm6.1 - 安装命令:Bash
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm6.1
- Index URL:
4. 📝 环境变量速查表 (Cheat Sheet)
在 docker-compose.yml 或 .bashrc 中必须配置的关键变量:
- 显卡伪装 (HSA Override):
- RX 7000 系列 (RDNA3):
HSA_OVERRIDE_GFX_VERSION=11.0.0 - RX 6000 系列 (RDNA2):
HSA_OVERRIDE_GFX_VERSION=10.3.0
- RX 7000 系列 (RDNA3):
- 解决绘图花屏 (SDMA):
HSA_ENABLE_SDMA=0
- Ollama 显存释放 (配合 ComfyUI 使用):
OLLAMA_KEEP_ALIVE=0